
技術者として、気づいたこと、感じたこと、困ったことなどを書き連ねていこうと思います。この先気づいたことがあれば増やしていきたいとおもいます。
間違いなどあると思います。業務で利用する場合、そのまま鵜呑みにしないようにお願いします。できるだけ責任のある情報を載せたいと思います。訂正等ありましたら、ご連絡いただけると幸いです。
技術メモ もあります。
インデックス
- DBで日付を扱う時の操作
- LINUXでファイルの一覧から特定文字を含むファイルを表示する
- コマンドプロンプトで画面をクリアする方法
- Oracleで表示件数を絞り込む方法
- ファイルダウンロード
- JavaScriptからテキスト文字を取得する
- エンコード
- SQL文のチューニング
- ORACLE IMP ツール
- JBuilderでTomcat使うときに sun/tools/javac/Main が見つかりませんエラーの対応
- 文字化けする文字一覧
- トークンの導入
- Shift_JISとWindows-31Jの相違点
- マテリアライズドビューの作り方
- マテリアライズドビューの更新(リフレッシュ)
- マテリアライズドビューの自動更新
- Oracleのデータベース文字コード
- AccessからOracleへのエクスポート
- DB2で抽出データ件数を指定する方法
- DBの型がDecimal型の場合は BigDecimal 型で受けよう
- 行ロックをかける
- ブラウザのキャッシュ戦略をぶっこわせ
- DB2でカナのソートについて
- みんなに使われるクラス
- DBのMAX_LENGTH とWEBのMAX_LENGTHは違う
- BigDecimal の double を引数にとるコンストラクタに注意
- HTMLのフォームエレメントを動的に作成する
- FTPバッチの作り方
- <%@ include %> と <jsp:include > の違い
- フォームの属性を囲むクォートは「”」にするべし
- HTMLリファレンス文字列一覧
- Command パターン
- 検証(verification)と妥当性(validation)
- Exception クラスの派生
- 不正チェック
- Excel のエスケープシーケンス
- Windowsで名前解決する方法
- 日付型の配列を使う場合 long型の配列で保持する
- ファイルのパスとリソースのパスの違い
- SQL文の動的条件追加
- 表の結合順序と効率
- SessionBeanの賢い使い方
- EJBの設計
- Oracleの空文字の扱い 2004/7/14追加
- 依存関係逆転の法則 2004/7/15追加
- String.replaceメソッドでString index out of rangeがでる 2004/8/23追加
- 実装の継承とインターフェイスの継承 2004/10/1追加
- linuxで変なファイル名が出来ちゃったときに消す方法 2004/10/21追加
- メールアドレスの@より前に使える文字 2004/10/26追加
- 行ロックとマルチスレッドとトランザクションを考える 2004/10/27追加
- Tomcat で lib に xdoclet 関連のライブラリがあると例外 2004/11/05追加
- JavaBeanの定義 2004/11/09追加
- JSP2.0 の web.xml 定義 2004/11/10追加
- WinSCP でログイン時にリストの取得でエラーが起こる 2004/12/04追加
- SSH接続で公開鍵認証を使うときに、公開鍵を authorized_keys にコピーし忘れないようにしましょう 2004/12/04追加
- 要求モデリングのポイント 2004/12/10追加
- マウス右クリックしたフォルダからコマンドプロンプトを開く 2004/12/13追加
- プロジェクト管理における7つの鉄則 2005/1/13追加
- Authorization(承認) と Authentication(認証) 2005/1/16追加
- ホームページ・Flashのテンプレート、テンプレートモンスター 2005/1/24追加
- JDBCドライバのタイプの違い2005/2/9追加
- Linuxでファイルの文字コードを調べる方法 2005/2/10追加
- モデリング共通パターン 2005/2/28追加
- find, grep, nkf を使って、ファイルの中身を検索
- メールの件名で日本語を使うと文字化けする 2005/8/16追加
- ログイン後にすぐにセッションが切れてしまう 2006/2/9追加
- XML Schema の SchemaLocation 2006/6/6追加
- ラジオボタンのチェックを文字をクリックでも行えるようにする 2006/7/14追加
- IEでSSLでのファイルダウンロードに失敗する 2007/3/1追加
- マウス右クリックしたフォルダからCygwinを開く 2007/4/20追加
ノウハウ一覧
DBで日付を扱う時の操作
GregorianCalendar cal = new GregorianCalendar(2002, 9 - 1, 27, 15, 15, 15);
java.util.Date date = cal.getTime();
long time = date.getTime();
Timestamp timestamp = new Timestamp(time); LINUXでファイルの一覧から特定文字を含むファイルを表示する
> find . -type f -name "*.jsp" -exec grep -l 検索文字 {} \;
コマンドプロンプトで画面をクリアする方法
- windows: clsコマンド
- unix,linux: Ctrl + L
Oracleで表示件数を絞り込む方法
結果の最初から10件のみ表示する
SELECT * FROM DUAL WHERE ROWNUM <= 10;
検索結果の10件目から15件目をとりたい場合は、ROWNUMは使えません。どうするのかというと、row_number()という問い合わせ関数を使います。(Oracle 9i 以上)
SELECT 受注数, 受注者名, 型番 FROM (SELECT row_number() over (ORDER BY 受注数) rn, 受注数, 受注者名, 型番 FROM 受注テーブル ) WHERE 10[参考URL]
ファイルダウンロード
response.setContentType("application/octet-stream");
response.setHeader("Content-Disposition", "inline; filename=\"" + filename + "\"");
JavaScriptからテキスト文字を取得する
span タグに id をつけて、 id.innerHTML で、spanタグに囲まれたテキストが取得できる
document.all("fieldName").innerHTML;
エンコード
Javaでは文字を格納するデータ型として char と byte を使います。Unicode文字の場合には char型を、Unicode文字以外のエンコーディングの場合には byte型を使用します。
EUCで byte配列に格納していた文字列をStringに直すときは new String(byte[], “EUC-JP”);
String文字列をEUC-JPのbyte配列として取得するには String.getBytes(“EUC-JP”);
ファイルダウンロードなどでエンコードするときは PrintWriter を使わない。PrintWriter はデフォルトのエンコーディングを使っている。InputStream OutputStream を使用する
SQL文のチューニング
SQL*PLUS で set autotrace on とするとインデックスが使用されているかされていないかをチェック出来る。
SQLの発行にかかった時間を取得するには set timing on とする。
ORACLE IMP ツール
ダンプファイルのインポートをする場合 IMP を使う。一件ずつコミットする場合 imp system/manager@dbname commit=y とする。
JBuilderでTomcat使うときに sun/tools/javac/Main が見つかりませんエラーの対応
C:\JBuilder8\jdk1.4\ の下に lib フォルダが有り、 tools.jar があるかを確認
文字化けする文字一覧
ソ噂浬欺圭構蚕十申曾箪貼能表暴予禄兔喀媾彌拿杤歃濬畚秉綵臀藹觸軆鐔饅鷭
トークンの導入
Webで問題となる2度押しやブックマークなどの問題に トークン を導入する。
[参考]
Shift_JISとWindows-31Jの相違点
参考
“Shift_JIS”と”Windows-31J”は,IANAに正式に登録されている文字集合の名称であり,前者はJIS X 0208で定められており,後者はMicrosoftのコードページ932に相当します.この2つの文字集合には,次のような重要な違いがあります.
1.収録されている文字が異なります.たとえば,Windows-31JはNEC特殊文字,IBM特殊文字を含んでいますが,Shift_JISは含んでいません. 2.Windows-31Jは,MS-DOSにおけるNECやIBMの拡張した文字群を収録していますが,一部の重複している文字は,Unicodeの同じコードポイントに割り当てられています.このために,一度読み込んでUnicodeに変換してしまうと,元のファイルに戻すことができないことがあります. 3.一部の文字に対して,Unicodeに変換する際のコードポイントが違います(〜, ‖, −, ¢, £, ¬など).
特に最後の違いがあるために,JavaのようなUnicodeベースの環境では,単純にWindows-31JをShift_JISのスーパーセットとして扱うことはできないことに注意してください.
「今回の修正の影響範囲と対処方法」
今回の修正の影響範囲と対処方法は,次の通りです.
1, プログラムやデータ,通信で"Shift_JIS"と明示的に指定していない/されない場合
プログラムの実行に影響はありません.
2, プログラムやデータ,通信で"Shift_JIS"と明示的に指定している/される場合
ほとんどがWindows-31Jを用いたデータを扱っているにもかかわらず,
誤って"Shift_JIS"と指定していた場合だと思いますが,
拡張された文字や一部の記号類(〜, ‖, −)が'?'に文字化けしますので,
正しく"Windows-31J"と指定してください.なお,この修正は1.4.1bを待つ必要はありません.
a) Servletの場合
res.setContentType("text/html; charset=Windows-31J");
PrintWriter out = res.getWriter();
b) JSPの場合
<%@ page contentType="text/html; charset=Windows-31J" %>
3, "MS932"と明示的に指定していた場合
プログラムの実行に影響はありません.
ただし,"Windows-31J"に書き換えることを薦めます.なお,この修正は1.4.1bを待つ必要はありません.
4, "SJIS"と明示的に指定していた場合
プログラムの実行に影響はありません.
1.4.1b以降では,"Shift_JIS"でも正しく動作するようになりますので,"Shift_JIS"に書き換えてください.
マテリアライズドビューの作り方
CREATE MATERIALIZED VIEW m_view ←ビュー名 AS SELECT deptno,AVG(sal) FROM emp GROUP BY deptno ←元データのSELECT文
マテリアライズドビューの更新(リフレッシュ)
手動で単一のスナップショットをリフレッシュする
execute dbms_snapshot.refresh('XXXX','?');
注)XXXXはスナップショット名
オプションの種類
- ‘f’
- 高速リフレッシュ
- ‘c’
- 完全リフレッシュ
- ’?’
- デフォルトのリフレッシュ
マテリアライズドビューの自動更新
CREATE MATERIALIZED VIEW m_view ←ビュー名 REFRESH FORCE ON COMMIT
ただし、 distinct を指定した SELECT 文の時は指定できない。
Oracleのデータベース文字コード
Oracleデータベースを作る際は、Shift_JIS の文字コード + ‘〜’ を登録可能とする。文字コード、 SJISTIRDA と言うものがある。
AccessからOracleへのエクスポート
最初に、Oracle Net Manager にサービス・ネーミングを作成し、その名前でAccessからエクスポートする。Oracle Net Manager で作成しない場合、 Enterprise Manager で接続を作成すると XXX_192.168.0.X というサービス・ネーミングが作成される。この名前でも Access からエクスポートできる。 エクスポートする前に、 ODBC の接続を作成しておく必要がある。「管理ツール」のデータソースでデータソースを作成し、それを上で作ったサービスに結びつける。 あとは、Access からエクスポートを選ぶだけ。
DB2で抽出データ件数を指定する方法
SELECT * FROM XXX fetch first 10 rows only
DBの型がDecimal型の場合は BigDecimal 型で受けよう
DBの型が Decimal 型の場合は Java 側では BigDecimal 型で受けるべし。
行ロックをかける
問い合わせで行ロックする方法として、for update 句がある。for update nowait は、ロック解除を待たずにエラーを返す。次の例は、ロックされていたら待って問い合わせる。
select * from testm where key = 'a001' for update;
nowait はエラー構文となった。
select * from testm where key = 'a001' for update nowait;
java.lang.String の replaceAll
replaceAll の リプレース文字列(第二引数)に $ が付くとエラーになる。対応は $ を \$ にする。 プログラムで $ を \$ に直すには以下のようにする。
str.replaceAll("\\$", "\\\\\\$");
ブラウザのキャッシュ戦略をぶっこわせ
<meta http-equiv="Pragma" content="no-cache"> <meta http-equiv="Cache-Control" content="no-cache"> <meta http-equiv="expires" content="Sun, 10 Jan 1990 01:01:01 GMT">
DB2でカナのソートについて
カナのソート(SELECT)の方法(単純にorder byにすると一部並びがおかしくなる。)
ORDER BY HEX(SUBSTR(項目名,スタート位置,桁数)) 例 order by hex(substr(kaisha_kana,1,20))
みんなに使われるクラス
意図しない使われ方をしないように作りましょう。たとえば、コンストラクタの公開キーワードを private にするとか。
DBのMAX_LENGTH とWEBのMAX_LENGTHは違う
DBのMAX_LENGTH はバイトで計られることが多い -> 10バイト(日本語は5文字)
WEBのフォームのMAX_LENGTH は文字数 -> 10文字(日本語10文字入る)
BigDecimal の double を引数にとるコンストラクタに注意
このコンストラクタの結果は予想外である可能性があります。new BigDecimal(.1) は正確に .1 と等しいと思われるかもしれませんが、実際には .1000000000000000055511151231257827021181583404541015625 となります。
これは .1 を double (または有限長 2 進小数) として正確に表現できないためです。したがって、コンストラクタに渡されている long 値は正確に .1 と等しいわけではありません。
一方、String を引数とするコンストラクタは予測可能です。new BigDecimal(“.1”) は、「正確に」 .1 と等しくなります。
そのため、通常は、double を引数とするコンストラクタの代わりにString を引数とするコンストラクタを使用することをお勧めします。
HTMLのフォームエレメントを動的に作成する
document.all.span_id.insertAdjacentHTML('afterBegin', '<INPUT type="text" name="ero" value="hoge">');
<span id="span_id"></span>
上記JavaScriptで span タグの後ろにフォームエレメントができる!
Jakarta Commons
訳すと関数インターフェイスでしょうか。コレクションの各要素に対して、f(x)の処理を行うインターフェイス群です。以下のようなものがあります。
- Factory Object create()
- 作る
- Predicate boolean evaluate(Object input)
- 判定する
- Closure void execute(Object input)
- 実行する
- Transformer Object transform(Object input)
- 変換する
FTPバッチの作り方
ftp -s:test.scr <- バッチ1 でこのように書く guest <- test.scr ファイルにこのように書く(ユーザID) guest <- (パスワード) put file1 <- コマンド quit
<%@ include %> と <jsp:include > の違い
<%@ include %>
このタグによって指定されたファイルは、JSPがサーブレットのファイルに変換される前に、JSPの一部としてインクルードされます。そして、インクルードされたものを含めてサーブレットに変換されてから実行されます。このタグでインクルードされたファイルが更新されても、JSP自体が更新されなければJSPに更新は反映されません。
<jsp:include >
このタグは、指定されたファイルをJSPの一部としてインクルードするのではなく、指定されたURLにリクエストを送信し、その応答内容を動的にリクエスト元に挿入して表示します。インクルードされるページとインクルードを行うJSPとは独立したページとして存在するため、インクルードされたファイルが更新されれば、元のJSP自体が更新されていなくても、動的に更新内容が結果に反映されます。
フォームの属性を囲むクォートは「”」にするべし
<input type=“text”> 等の属性を囲むクォートは「”」にしたほうがよい。なぜなら、初期値として「”」を含むような値を表示したい場合「"」を使用して「”」を表示すればよい。シングルクウォート「’」を表示する場合「'」を使用する。
HTMLリファレンス文字列一覧
" -> " < -> < > -> > & -> & 空白文字-> the letter "a" with a small circle above it -> å the Cyrillic capital letter "I". -> И the Chinese character for water -> 水
Commandパターン
One important purpose of the Command pattern is to keep the program and user interface objects completely separate from the actions that they initiate.
コマンドパターンの重要な目的の一つに、プログラムとユーザインターフェースオブジェクトをコマンドの起動者から完全に切り離すということがある。・・・つまりコマンドの起動者はコマンドがどのように動くかということは知らなくてよくなる。(コマンドが何をするかは知る必要があると思うが)
検証(verification)と妥当性(validation)
知識の「正しさ」を知る方法には実は2種類ある(「正しさ」に2種類あるといってもいい)。
1つは検証(verification)と呼ばれるもの、もう1つは妥当性確認(validation)と呼ばれるものだ。この使い分けは微妙で難しいが(分野によっても違うかもしれない)、大ざっぱにいうと
- 検証とは自分たちがこういうものを作ろうと決めたとおりにできているかどうかを確かめること、
- 妥当性確認とはできたものが本当に欲しかったものかどうかを確かめることだ
例えばテスト仕様書を書き、テスト仕様に従ってソフトウェアを実行したときにどのような答えが出るかをチェックする。これが検証。検証できたからといって、そのソフトウェアが「本当に」正しいとは限らない。
だって仕様書にすべての場合を列挙することはできないし、そもそも仕様書が顧客の意図したものになっているとは限らない。それに対してユーザーや顧客が欲しかったソフトウェアになっているかどうかをチェックするのが妥当性確認。
Exception クラスの派生
Exception クラスを派生させてエラーオブジェクトを作るときは、エラーコードを持たせられるといいかも。ってか、エラー処理機構をアーキテクチャ的に考えよう!
不正チェック
「不正な」データ値をチェックするのは間違いなのです。それよりも、何が「正しい 」のかをきちんと決め、データがその定義に合致しているかをチェックし、その定義に合致しないデータはどんなものでも拒否するようにすべきなのです。
通常表現を使って一致をチェックする場合には必ず、データの最初(通常、^記号が付きます)と最後(通常、$が付きます)が一致することをチェックするようにしてください。
理想的にはユーザーにファイル名を選ばせないようにするか、それができなければ文字を小さなパターン、例えば
^[A-Za-z0-9][A-Za-z0-9._\-]*$に限定するようにします。
ユーザーが攻撃者かも知れないので、ロケール値を検証する必要があります。私はロケールが次のパターンに一致するかどうかを確認するようにお勧めしたいと思います。
^[A-Za-z][A-Za-z0-9_,+@\-\.=]*$
クッキー
Webアプリケーションではよく、重要なデータにクッキーの値を使います。後ほど説明しますが、ユーザーがクッキーの値やフォームのデータをリセットして、ユーザーの好きなように設定できることは重要ですので良く覚えておいてください。
それとは別に、ここで言っておいた方が良い検証のトリックがあるのです。もしクッキーの値を受け付ける場合には、そのドメイン値が想定したもの(つまりあなたのサイトの一つ)に なっていることをチェックしてください。そうしないと、(おそらく改変された)関連のサイトが、変なクッキーを挿入できてしまうかも知れないのです。
この攻撃がどのように動作するかに興味があれば、IETF RFC 2965に詳細が説明されています(参考文献にリンクがあります)。
[参考]
Excel のエスケープシーケンス ~
Excel のエスケープシーケンスは ~(チルダ)
Windowsで名前解決する方法
C:\Windows\system32\drivers\etc\hosts
に IP と 名前 を書くと、そのWindowsでDNSの名前解決ができる。
日付型の配列を使う場合 long型の配列で保持する
Date型の配列で日付を保持するより、long型で日付を保持したほうがパフォーマンスも良いし、何かと便利。
ファイルのパスとリソースのパスの違い
ファイルのパスは、現在の場所からの相対・絶対パスになる。リソースのパスは、クラスパスが通ったところからの相対・絶対パスになる。
Javaの実装例: FileInputStream#FileInputStream(); Class#getResourceAsStream();
SQL文の動的条件追加
(2004/6/27追加)
動的条件を付け足すときに、最初から 「1=1」のような条件を WHERE 句につけておくと便利。
StringBuffer sql = new StringBuffer("SELECT * FROM TABLE_NAME WHERE 1=1");
if (isInput()) {
sql.append(" AND COLUMN = 'hoge' ");
}
if (isInput2()) {
sql.append(" AND COLUMN2 = 'foo' ");
}
上記のように、どの条件が最初に来るかわからない場合でも、「AND」から条件を付け始められる。
表の結合順序と効率
(2004/6/30追加)(oracleにて)
ネストされたループ結合では、「処理対象件数の少ない表を外部表にする」「結合列に索引が存在し、その索引によって効率的にアクセス可能な表を内部表とする」「外部表に件数が少ないほうが効率がよい。」
ソート・マージ結合では、それぞれの表をソートし、双方のソート済みのデータを上から順番に付き合わせて、一致する行同士を結合します。
ハッシュ結合では、「結合する2つの表でデータ量の少ない表の結合列にハッシュ関数を適用」「データ量の多いほうの結合列にもハッシュ関数を適用」「ハッシュと結合」ハッシュ結合は等結合(=)を指定している場合のみ、利用できる
結合順序は、ルールベースの場合、FROM句に指定した表の打ち、後ろに記述した表から順に結合される。CBOでは、オプティマイザによって順序がきめられる。ヒント句を指定できる。
SessionBeanの賢い使い方
(2004/7/7追加)
EJBで使用するSession Beanは、システムの分析時に作成したユースケースの単位で作成すると良い。システムの構成がシンプルになり、保守しやすくなる。
Session BeanからSession Beanを呼び出す場合はリモートインターフェースを使うと分散環境を構築しやすくなる。ただし、リモート呼び出しになるため、パフォーマンスなどのコストがかかるので、Session BeanからSession Beanを呼び出す処理を多用するのは避ける。
EJBのクライアントからSession Beanを直接呼び出すと、密結合となりシステムの柔軟性が落ちる。解決策として、EJBクライアントからのリクエストを受け取り、Session Beanを呼び出すクラスを作る。このクラスはPOJI(Plain Old Java Object)として作成すればよい。
このように、Session Beanを呼び出す処理を委譲する設計を「Business Delegateパターン」という。プレゼンテーション層とサービス層を分離できるので、保守が容易になる。MVCパターンでいう、C(コントローラ)を作るイメージです)
[参考]
EntityBeanの設計
(2004/7/7追加)
Entity Beanは本来、オブジェクト指向の観点からドメインモデルを作成しそれに沿って作るのが望ましい。が、従来のデータベース設計からはじめた場合は、ER図をベースにドメインモデルを作り、Entity Bean を作る方が設計は上手くいくと思う。
Entity Beanはローカルインターフェースを実装し、EJBクライアントから直接呼び出せないようにする。これによって、呼び出しによるパフォーマンスが向上するほか、プレゼンテーション層とインテグレーション層を確実に分離できる。
Entity Beanにローカルインターフェースを実装させた場合、呼び出しは同一マシン上に配置したSession Beanから呼び出すようにする。
EJBの設計
(2004/7/7追加)
Enterprise Beanを作る際に、コールバックメソッド(ejbCreateやejbActivateなどのメソッド)を実装する必要があるが、コールバックメソッドを実装したAdapterクラスを作ると便利である。
各Enterprise Beanは、Adapterクラスを継承するようにすることで、個別にコールバックメソッドを実装sるう必要がなくなる。
Oracleの空文字の扱い
(2004/7/14追加)
Oracleでは、空文字と null の区別がない。insertで空文字を登録しても実際は null として登録される。DB2やSQL Serverはきちんと空文字と null とを区別する。
[参考]
依存関係逆転の法則
(2004/7/15追加)
上位のモジュールは下位のモジュールに依存してはならない。どちらのモジュールも「抽象」に依存すべきである。
「抽象」は実装の詳細に依存してはならない。実装の詳細が「抽象」に依存すべきである。
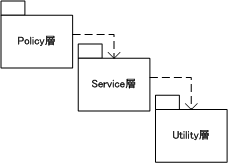
上記の図は、上位モジュールであるPolicy層が下位モジュールのService層やUtility層に依存してしまっている。この依存関係を反転させたのが下記の図である。
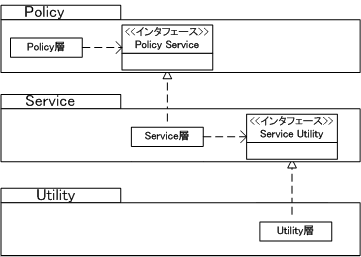
上位のモジュールは、下位のモジュールに依存しなくなっている。注目なのは、下位のモジュールが、上位モジュールと同レベルの「抽象」に依存した点である。このように、上位のモジュールがインターフェースを宣言し、下位のレベルのモジュールはそれに従った実装を請け負うのが、真のオブジェクト指向である。
[参考]
String.replaceメソッドでString index out of rangeがでる
(2004/8/23追加)
String.replaceFirst や String.replaceAll メソッドで、正規表現で使われるエスケープ文字が使われると、String index out of range エラーが発生します。これを回避するには、下記の様に正規表現エスケープ文字をエスケープする必要があります。
/**
* target 文字列の pattern にマッチする最初の文字列を replace 文字列で置き換える。
* java.lang.String の replaceAll で '$' が replace に含まれていると
* エラーが出るものに対応
* @param target 変換対象文字列
* @param pattern 変換パターン
* @param replace 変換文字列
* @return 変換後の文字列を返します。
* @author Syougo Hamada
*/
public static String replaceFirst(String target, String pattern, String replace) {
String escape = replace.replaceAll("\\\\", "\\\\\\\\"); // エスケープ文字のエスケープ
return target.replaceFirst(pattern, escape.replaceAll("\\$", "\\\\\\$"));
}
実装の継承とインターフェイスの継承
(2004/10/1追加)
継承には、実装の継承とインターフェイスの継承とがある。実装の継承とは、Javaでいう extends を使う方法である。インターフェイスの継承とはJavaでいう implements を使う方法である。
使い分けるルールとしては
- クラスが「もの」や「こと」の種類を表している場合は実装の継承
- サービス、機能を継承する場合はインターフェイスの継承
[参考]
- 『軽快なJava』 オライリージャパン
linuxで変なファイル名が出来ちゃったときに消す方法
(2004/10/21追加)
Linuxを使っていて、たまに変なファイル名を付けちゃったときに消す方法です。変なファイル名というのは、例えば「スペース」「\」「-」「*」とか入れちゃった場合です。
【ファイル名を「’ (シングルクウォート)」で囲む方法】
消せるファイル種類 ・「スペース」が入っているファイル名 例: rm 'Program Files' ・「#」で囲まれているファイル名 例: rm '#back_file#' ・「\」だけのファイル名 例: rm '\' ・「*」の入ったファイル名 例: rm '****' ・「~ユーザ名」と同じファイル名 例: rm '~hamasyou'
【「’」(シングルクウォート)を\(エスケープ)する方法】
消せるファイル種類 ・「'」が入っているファイル名 例: rm \'\'
【「–」でオプションを無効化する方法】
消せるファイル種類 ・「-」が先頭にあるファイル 例: rm -- -exclude
[参考]
メールアドレスの@より前に使える文字
(2004/10/26追加)
メールアドレスの「@」よりも前につかえる文字の一覧です。
- 英数字
- ! (エクスクラメーションマーク)
- # (いげた)
- $ (ドルマーク)
- % (パーセント)
- & (アンパサンド)
- ’ (シングルクウォート)
- + (プラス)
- - (マイナス)
- / (スラッシュ)
- ? (クエスチョンマーク)
- ^ (カレット) _ (アンダーバー)
- ` (バッククウォート)
- { (中括弧開く)
- | (パイプライン)
- } (中括弧閉じる)
- ~ (チルダ)
- . (ピリオド)
` (バッククウォート) や $ (ドルマーク) が使えるとは、結構びっくりでした。サーバ側でメールアドレスの処理をするときは、サニタイジング を忘れないようにしましょう。
なお、使用にはいくつか制約があるので注意。例えば ".(ピリオド)" はテキスト文字に囲まれているときのみ利用可能で、ピリオドの連続や、@の直前のピリオドは無効となります。詳しくは、参考リンクを参照のこと。
[参考]
行ロックとマルチスレッドとトランザクションを考える
(2004/10/27追加)
業務ロジックで、「DBに登録してあるIDをインクリメントして使う」という処理があるとします。例えば、下記のようなテーブル構成があるとします(テーブルの中身についてはつっこみはなしでお願いします・・・)

このテーブルでは、「従業員テーブルのEMP_ID」と「従業員IDテーブルのEMP_ID」が参照関係にあります。ここでは、下記のルールを元に考えます。
1. 従業員テーブル(以下EMPT)のEMP_IDは、従業員IDテーブル(以下IDT)のEMP_IDを元に決められる。 2. 一度使われたIDTのEMP_IDはインクリメントされる
ここで考えられる処理としては、
IDTから現在の最大EMP_IDを取り出して、インクリメントしたものをもとに、EMPTのEMP_IDを決めてインサート処理を行う。その後、IDTのEMP_IDを更新する。
というのがあります。ソースコードにすると、こんな感じですか。
public void insertNewEmployee(long companyID) {
long currentEmpID = getLastEmpID(companyID);
Employee newEmp = new Employee(companyID, currentEmpID + 1);
newEmp.save();
saveLastEmpID(companyID, currentEmpID + 1);
}
private long getLastEmpID(long companyID) {
// select EMP_ID from EMP_ID_TABLE where COMPANY_ID = x
return 現在の最後の従業員IDをかえす
}
private void saveLastEmpID(long companyID, long empID) {
// update EMP_ID_TABLE set EMP_ID = x where COMPANY_ID = y
}
細かい処理は省いています。この処理には、かなり致命的だけど、実際に起こってみるまでわかりにくいバグが潜んでいます。
問題点は?
上記処理の問題点は2つあります。一つ目に、insertNewEmployee メソッドがマルチスレッド環境化では登録者IDが重複してしまう可能性があるという点です。二つ目に、getLastEmpID メソッド内の select文 が、排他ロックになっていないことです。
マルチスレッド環境化で実行されて2行目と3行目の間で割り込みが発生すると、同じ従業員IDが割り振られる可能性があります。また、select文が排他ロックになっていないので、2行目が実行された後に、他のアプリケーションから従業員IDを変更されてしまう可能性があります。
問題点改善後のソースコード
public synchronized void insertNewEmployee(long companyID) {
// 後は同じ
}
public long getLastEmpID(long companyID) {
// 排他的ロックをかけて、他から更新されないようにする
// select EMP_ID from EMP_ID_TABLE where COMPANY_ID = x
// for update
return 現在の最後の従業員IDを返す
}
private void saveLastEmpID(long companyID, long empID) {
// 同じ
}
insertNewEmployee メソッドを synchronized にして、7行目の select文に排他ロックをかけました。
結局 結局言いたいことは、主キーとなるIDを生成する場合は、DBMSの機能を使うか、確実に一つの値しか生成されないように工夫する(今回のように select for update文を使うとか)ようにしましょう。
免責: 上記のソースコードを利用したいかなる問題も責任は負いかねます。 (^^;
Tomcat で lib に xdoclet 関連のライブラリがあると例外
Tomcat を動かすときに、 Webアプリケーションで XDoclet 関連のライブラリ (xdoclet-1.2.jar, xdoclet-ojb-module-1.2.jar, xdoclet-xdoclet-module-1.2.jar and xjavadoc-1.0.2.jar) があると下記の例外が発生する可能性がある。
情報: Starting Servlet Engine: Apache Tomcat/5.0.19 2004/11/05 12:04:29 org.apache.catalina.core.StandardHost start 情報: XML検証は無効です java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:324) at org.apache.catalina.startup.Bootstrap.start(Bootstrap.java:297) at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:398) Caused by: java.lang.IllegalArgumentException: javacc,ant,commons-collections,commons-logging,log4j,junit-Extension-Name at java.util.jar.Attributes$Name.<init>(Attributes.java:434) at java.util.jar.Attributes.getValue(Attributes.java:97) at org.apache.catalina.util.ManifestResource.getRequiredExtensions(ManifestResource.java:243) at org.apache.catalina.util.ManifestResource.processManifest(ManifestResource.java:212) at org.apache.catalina.util.ManifestResource.<init>(ManifestResource.java:96) at org.apache.catalina.util.ExtensionValidator.validateApplication(ExtensionValidator.java:250) at org.apache.catalina.core.StandardContext.start(StandardContext.java:4133) at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1126) at org.apache.catalina.core.StandardHost.start(StandardHost.java:832) at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1126) at org.apache.catalina.core.StandardEngine.start(StandardEngine.java:521) at org.apache.catalina.core.StandardService.start(StandardService.java:519) at org.apache.catalina.core.StandardServer.start(StandardServer.java:2345) at org.apache.catalina.startup.Catalina.start(Catalina.java:594) ... 6 more
対処法は、XDoclet 関連のライブラリを含めないことかな?
[参考]
JavaBeanの定義
(2004/11/09追加)
JavaBean とは 「再利用可能なソフトウェアコンポーネント」です。
- プロパティ
設定可能な内部状態のこと。読み取り専用のプロパティもあるが、通常は、「読み書きの出来るフィールド」だと思えばよい。
- イベント
内部状態に変化があったことを通知するもの。なんらかの処理が行われた場合に起こる。
- メソッド
コンポーネントに対して行わせたい処理を呼び出す手段。例えば、計算や画面表示など。
JavaBean の特性
- Simple 特性
一つのプロパティに対して対となる get/set メソッドが用意されている。
- Indexed 特性
配列やリストを取るプロパティに対して、全体を get/set できるメソッドが用意されている。また、個別の要素に対して、インデックスでアクセスできる get/set が用意されている。
- Bound 特性
コンポーネントの内部状態に変更が起こった場合、適切なイベントが発生する。例えば、コンポーネントの状態が変更された場合、それに紐付くコンポーネントや、バインドされたコンポーネントにも、変更が通知される。
- Constrained 特性
コンポーネントの内部状態に変化が起こった場合、それに関連するオブジェクトの状態も適切に変化させる。
プログラム中で JavaBean を表現するときには、デフォルトコンストラクタと、プロパティに対する get/set メソッドを定義しておけば、標準の JavaBean として扱えると思います。
[参考]
JSP2.0 の web.xml 定義
JSP 2.0 から web.xml の書き方が変わったようです。
<?xml version="1.0" ?>
<web-app xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://
java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"
version="2.4">
<!-- xsi:schemaLocation は本当は一行で書く -->
タグリブの定義の仕方も少し変わったみたいです。「jsp-config」というタグで囲む必要があります。(囲まないでも大丈夫!?)
<jsp-config>
<taglib>
<taglib-uri>/spring</taglib-uri>
<taglib-location>
/WEB-INF/lib/spring.tld
</taglib-location>
</taglib>
</jsp-config>
ELバージョンのJSTL coreライブラリー用taglib指示子
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
formatライブラリ用のtaglib指示子
<%@ taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="fmt" %>
[参考]
WinSCP でログイン時にリストの取得でエラーが起こる
[参考]
これは接続先のlsのエイリアス設定やLANGなどの環境変数によって生じるエラーです。 WinSCPのオプション(「エイリアスのクリア」や「環境変数のクリア」)で解決できる場合もありますが、 できない場合には以下の方法から1つ選んで対応してください。
- WinSCPのログイン画面→[環境]→[SCP]のシェルで[入力]を選択し、”/bin/bash” と入力する。
- サーバ側の ~/.login ファイルに次のように記述する(csh系の場合)。
if ($?SSH_CLIENT && ! $?SSH_TTY) setenv LANG C
SSH接続で公開鍵認証を使うときに、公開鍵を authorized_keys にコピーし忘れないようにしましょう
SSHで接続するときに、公開鍵認証方式を使って接続する場合に、 サーバーにOpenSSH を使っている場合の注意点。
公開鍵と秘密鍵をクライアントマシンで作ったあと、公開鍵をサーバーにアップしなければなりません。その際、ファイル名は適当でいいのですが、authorized_keys ファイルに公開鍵の内容を書き写さないと、公開鍵を見つけてもらえませんでした。
要求モデリングのポイント
要求モデリング (概念モデリング)を行う際に、どんな点に気をつけたらいいかのメモ。
- コンテキストを理解する。(システムに名前をつける)
- システムのアクターを知る (システムを使う人を聞いていく)
- どんな機能が必要かを聞き出し、大まかにグルーピング(例:顧客管理、在庫管理、会計)
- 他機能と関係が多くなりそうな部分からモデリングをはじめる。
- 顧客からの情報 + 他のシステム(amazonとか)で使われている機能の情報などをあわせて、モデリングしていく
モデリングの視点を一つに決めることが重要。例えば、機能として「顧客管理」と「在庫管理」があった場合、主システムが「在庫管理」であれば、「在庫の注文」より「在庫の受注」として、在庫管理システムからの視点で記述する。
モデル化対象のシステムが、モデルに現れたらおかしくないか疑うべし。自社システムを開発している場合、モデル中に「自社」というエンティティが出てきたら、おかしい。
履歴を管理したい場合は、「期間」を限定子としてモデリングする。また、同一の時間軸でモデリングすること。ばらばらの時間軸で登場するモデルが存在すると、混乱する。
与えられたインスタンスを基に概念(型)を発見したり発明したりするのがモデリングだ。
マウス右クリックしたフォルダからコマンドプロンプトを開く
エクスプローラで、このフォルダから「コマンドプロンプト」を開きたい!と思うときありませんか?レジストリをいじると、フォルダを右クリックしてコマンドプロンプトを開くことができるようになります。以下手順です。
- 「スタート」->「ファイル名を指定して実行」で「regedit」と入力する
- 「HKEY_CLASSES_ROOT」 - 「Folder」 - 「shell」の下に、新規キーで適当なキーを作成する
- 作成したキーの「既定」をダブルクリックして、マウス右クリック時に表示される文言を入力する(例:ここからcmdを開く)
- 作成したキーにさらにサブキーとして、「command」というキーを作成する
- commandキーの「既定」をダブルクリックして、「cmd.exe」のパス + 「/k」 + 「cd "%L"」を設定する(例:「C:\WINDOWS\system32\cmd.exe /k cd "%L"」)
図1. 2,3番を実行した結果

図2. 4,5番を実行した結果

[参考]
※ レジストリをいじるので、自己責任で行ってください。
プロジェクト管理における7つの鉄則
- ドキュメンテーションよりもコミュニケーション
- ドキュメントは、コミュニケーションの手段にするべきです。ドキュメントは、メンテナンスコストがかかるので、本当に必要な場合以外は作成しないほうがよい。
- ファースト・トラッキング
- 「ファースト・トラッキング」と「クラッシング」を活用せよ